优化#
本页包含有关提高 JupyterHub 部署的可靠性、灵活性和稳定性的信息和指南。许多描述的设置仅旨在提供更好的自动扩缩体验。
总结来说,为了获得良好的自动扩缩体验,我们建议您:
启用 continuous image puller(持续镜像拉取器),为新增节点准备好用户镜像,以便用户抵达时使用。
启用 pod priority(Pod 优先级)并添加 user placeholders(用户占位符),以便在真实用户到达之前提前扩容节点。
启用 user scheduler(用户调度器),将用户紧密地打包到某些节点上,从而让其他节点变为空闲并可被缩容。
设置一个自动扩缩的节点池,并通过对节点进行污点(tainting)处理,并要求用户 Pod 容忍(tolerate)这些节点的污点以调度到这些节点上,从而将其专用于用户 Pod。这样,只有用户 Pod 会阻止节点缩容。
设置适当的用户资源 requests(请求)和 limits(限制),以允许合理数量的用户共享一个节点。
一个用于高效自动扩缩的合理最终配置可能如下所示:
scheduling:
userScheduler:
enabled: true
podPriority:
enabled: true
userPlaceholder:
enabled: true
replicas: 4
userPods:
nodeAffinity:
matchNodePurpose: require
cull:
enabled: true
timeout: 3600
every: 300
# The resources requested is very important to consider in
# relation to your machine type. If you have a n1-highmem-4 node
# on Google Cloud for example you get 4 cores and 26 GB of
# memory. With the configuration below you would be able to have
# at most about 50 users per node. This can be reasonable, but it
# may not be, it will depend on your users. Are they mostly
# writing and reading or are they mostly executing code?
singleuser:
cpu:
limit: 4
guarantee: 0.05
memory:
limit: 4G
guarantee: 512M
在用户到达前拉取镜像#
如果一个用户 Pod 被调度到一个请求了尚未被拉取到该节点的 Docker 镜像的节点上,用户将不得不等待。如果镜像很大,等待时间可能长达 5 到 10 分钟。这种情况通常发生在两种情况下:
引入了新的单用户镜像 (
helm upgrade)启用 hook-image-puller(默认启用)后,新引入的用户镜像将在 hub Pod 更新以使用新镜像之前被拉取到节点上。hook-image-puller 是一个技术名称,指的是使用 Helm hook 来实现此功能,一个更具信息性的名称应该是 pre-upgrade-image-puller。
注意:启用此功能后,如果您引入一个新镜像,您的
helm upgrade命令会花费很长时间,因为它会等待拉取完成。我们建议您在helm upgrade命令中添加--timeout 10m0s或类似的参数,以给予足够的时间。hook-image-puller 默认启用。要禁用它,请在您的
config.yaml中使用以下代码片段:prePuller: hook: enabled: false
添加了一个节点 (Cluster Autoscaler)
Kubernetes 集群中的节点数量可以增加,可以通过手动扩容集群大小或通过集群自动扩缩器(cluster autoscaler)。由于新节点是全新的,磁盘上没有任何镜像,因此到达此节点的用户 Pod 将被迫等待镜像被拉取。
启用 continuous-image-puller(默认启用)后,当新节点被添加时,用户的容器镜像将被拉取。新节点可以通过手动方式添加,也可以通过集群自动扩缩器添加。continuous image-puller 使用 daemonset 来强制 Kubernetes 在节点出现时立即在所有节点上拉取用户镜像。
continuous-image-puller 默认启用。要禁用它,请在您的
config.yaml中使用以下代码片段:prePuller: continuous: # NOTE: if used with a Cluster Autoscaler, also add user-placeholders enabled: false
需要注意的是,continuous-image-puller 结合集群自动扩缩器(CA)并不能保证减少用户的等待时间。它仅在 CA 在真实用户到达之前进行扩容时才有效,但 CA 通常无法做到这一点。这是因为它只会在一个或多个 Pod 无法适应当前节点但如果添加一个新节点就能适应时才会添加节点,但此时用户已经在等待了。为了提前扩容节点,我们可以使用 user-placeholders(用户占位符)。
将被拉取的镜像#
hook-image-puller 和 continuous-image-puller 有多种来源影响它们将拉取哪些镜像,因为它们需要提前为可能需要这些镜像的节点做准备。这些来源都可以在 Helm chart 提供的值中找到(可以通过 config.yaml 覆盖),路径如下:
相关镜像来源#
singleuser.imagesingleuser.profileList[].kubespawner_override.imagesingleuser.extraContainers[].imageprePuller.extraImages.someName
其他来源#
singleuser.networkTools.imageprePuller.pause.image
例如,使用以下配置,镜像拉取器将拉取三个镜像,以便为可能最终使用这些镜像的节点做准备。
singleuser:
image:
name: jupyter/minimal-notebook
tag: 2343e33dec46
profileList:
- display_name: "Minimal environment"
description: "To avoid too much bells and whistles: Python."
default: true
- display_name: "Datascience environment"
description: "If you want the additional bells and whistles: Python, R, and Julia."
kubespawner_override:
image: jupyter/datascience-notebook:2343e33dec46
prePuller:
extraImages:
my-other-image-i-want-pulled:
name: jupyter/all-spark-notebook
tag: 2343e33dec46
高效的集群自动扩缩#
一个 Cluster Autoscaler (CA) 将帮助您在集群中添加和移除节点。但 CA 需要一些帮助才能良好运行。没有帮助,它既无法在用户到达前进行扩容,也无法在不干扰用户的情况下足够积极地缩容节点。
及时扩容(用户占位符)#
集群自动扩缩器 (CA) 会在 Pod 无法适应可用节点但如果增加一个节点就能适应时增加节点。但是,这可能会导致 Pod 长时间等待,而 Pod 可能代表一个用户,因此会导致用户长时间等待。现在有解决这个问题的方法。
在 Kubernetes 1.11+ (需要 Helm 2.11+) 中,引入了 Pod 优先级和抢占。这允许具有较高优先级的 Pod 抢占/驱逐较低优先级的 Pod,如果这能帮助较高优先级的 Pod 适应节点。
这种优先级机制允许我们添加低优先级的虚拟用户或用户占位符,它们可以占用资源,直到一个真实用户(具有较高优先级)需要它。此时,低优先级的 Pod 将被抢占,为高优先级的 Pod 腾出空间。这个被驱逐的用户占位符现在能够向 CA 发出信号,表明需要进行扩容。
用户占位符将具有与 Helm chart 在 singleuser.cpu 和 singleuser.memory 下配置的相同的资源请求/限制。这意味着,如果您有三个用户占位符在运行,那么只有当超过三个用户在小于一个节点准备就绪所需的时间间隔内到达时,真实用户才需要等待扩容,前提是这些用户没有使用 singleuser.profileList 中指定的调整后的资源请求来启动。
例如,要使用三个用户占位符,它们可以通过 pod 优先级来完成任务,请添加以下配置:
scheduling:
podPriority:
enabled: true
userPlaceholder:
# Specify three dummy user pods will be used as placeholders
replicas: 3
关于用户占位符的进一步讨论,请参阅 @MinRK 的精彩帖子,他在其中分析了在 mybinder.org 上引入该功能的情况。
重要
根据您的集群自动扩缩器的配置,可能需要进一步的设置才能成功使用 Pod 优先级。这在 GKE 上是可行的,但我们不知道在其他云提供商或 Kubernetes 上是如何工作的。更多详情请参见配置参考。
高效缩容#
扩容是容易的部分,缩容则更难。要缩容一个节点,需要满足某些技术标准。核心的一点是,为了让一个节点被缩容,它必须没有不允许被中断的 Pod。不允许被中断的 Pod 包括真实的用户 Pod、重要的系统 Pod 和一些 JupyterHub Pod(没有一个宽松的 PodDisruptionBudget)。例如,考虑许多用户在白天到达您的 JupyterHub。CA 会添加新节点。出于某种原因,一些系统 Pod 与用户 Pod 一起最终落在了新节点上。到了晚上,当 culler 从一些节点上移除了许多不活跃的 Pod 后,这些节点上已经没有用户 Pod 了,但仍然有一个系统 Pod 阻止 CA 移除该节点。
为了避免这些缩容失败,我们建议为用户 Pod 使用一个专用的节点池。这样,所有重要的系统 Pod 都会在一个或有限的节点集上运行,因此自动扩缩的用户节点可以从 0 扩容到 X,再从 X 缩容回 0。
本节关于高效缩容的内容,也将解释用户调度器如何帮助您减少因阻塞用户 Pod 而导致的缩容失败。
为用户使用专用的节点池#
为了给用户 Pod 设置一个专用的节点池,我们可以使用 污点和容忍(taints and tolerations)。如果我们给节点池中的所有节点添加一个污点,并在用户 Pod 上添加一个容忍,以容忍被调度到带有污点的节点上,我们实际上就将该节点池专用于用户 Pod 了。
要让用户 Pod 调度到为它们专设的节点上,您需要执行以下操作:
设置一个节点池(带自动扩缩功能)、一个特定的标签和一个特定的污点。
如果您需要关于如何操作的帮助,请参考您的云提供商文档。节点池可能被称为节点组。
标签:
hub.jupyter.org/node-purpose=user注意:云提供商通常有自己的标签,与 Kubernetes 标签不同,但此标签必须是 Kubernetes 标签。
污点(taint):
hub.jupyter.org/dedicated=user:NoSchedule注意:由于云提供商的限制,您可能需要将
/替换为_。用户 Pod 可以容忍这两种污点。
要求用户 Pod 必须调度到上述设置的节点池中。
如果您不要求用户 Pod 调度到其专用节点上,您可能会占满运行其他软件的节点。这可能导致
helm upgrade命令失败。例如,您可能已经耗尽了非用户 Pod 的资源,这些 Pod 在滚动更新期间需要资源,但无法调度到自动扩缩的节点池上。默认设置是让用户 Pod 倾向于调度到带有
hub.jupyter.org/node-purpose=user标签的节点上,但您也可以使用以下配置使其成为必需的。scheduling: userPods: nodeAffinity: # matchNodePurpose valid options: # - ignore # - prefer (the default) # - require matchNodePurpose: require
注意:如果您最终不使用专为用户设置的节点池,但又想高效地进行缩容,您将需要了解 PodDisruptionBudget 资源,并做更多的工作,以避免出现几乎为空的节点无法缩容的情况。
禁用默认容忍#
某些集群可能运行着一个 PodTolerationRestriction admission-controller,它会阻止包含不在指定白名单内的容忍度的 Kubernetes 对象。如果您的集群正在运行此控制器,并且您无法更新它以包含 hub.jupyter.org/dedicated / _dedicated 容忍度,那么您可以通过将 scheduling.corePods.tolerations 和 scheduling.userPods.tolerations 设置为空列表来在所有 chart 的 Pod 中禁用这些容忍度。
高效利用可用节点(用户调度器)#
如果您有用户在启动新服务器,而活跃用户总数在减少,您将如何释放一个节点以便它可以被缩容?
这就是用户调度器能帮助您的地方。用户调度器的唯一任务是将新的用户 Pod 调度到利用率最高的节点。这可以与默认调度器相比较,后者总是尝试将 Pod 调度到利用率最低的节点。只有用户调度器才能允许利用率不足的节点随着用户总数的减少而逐渐被释放,即使仍有少数用户到达。
注意:如果您不想缩减您现有的节点,那么让用户分散并利用所有可用节点会更有意义。只有在您有自动扩缩的节点池时才激活用户调度器。
要查看用户调度器的实际效果,请看下面来自 mybinder.org 部署的图表。该图表是在首次启用用户调度器时绘制的,它显示了五个不同节点上活跃的用户 Pod 数量。当用户调度器启用后,两个节点及时地被清空了用户 Pod 并被缩容。
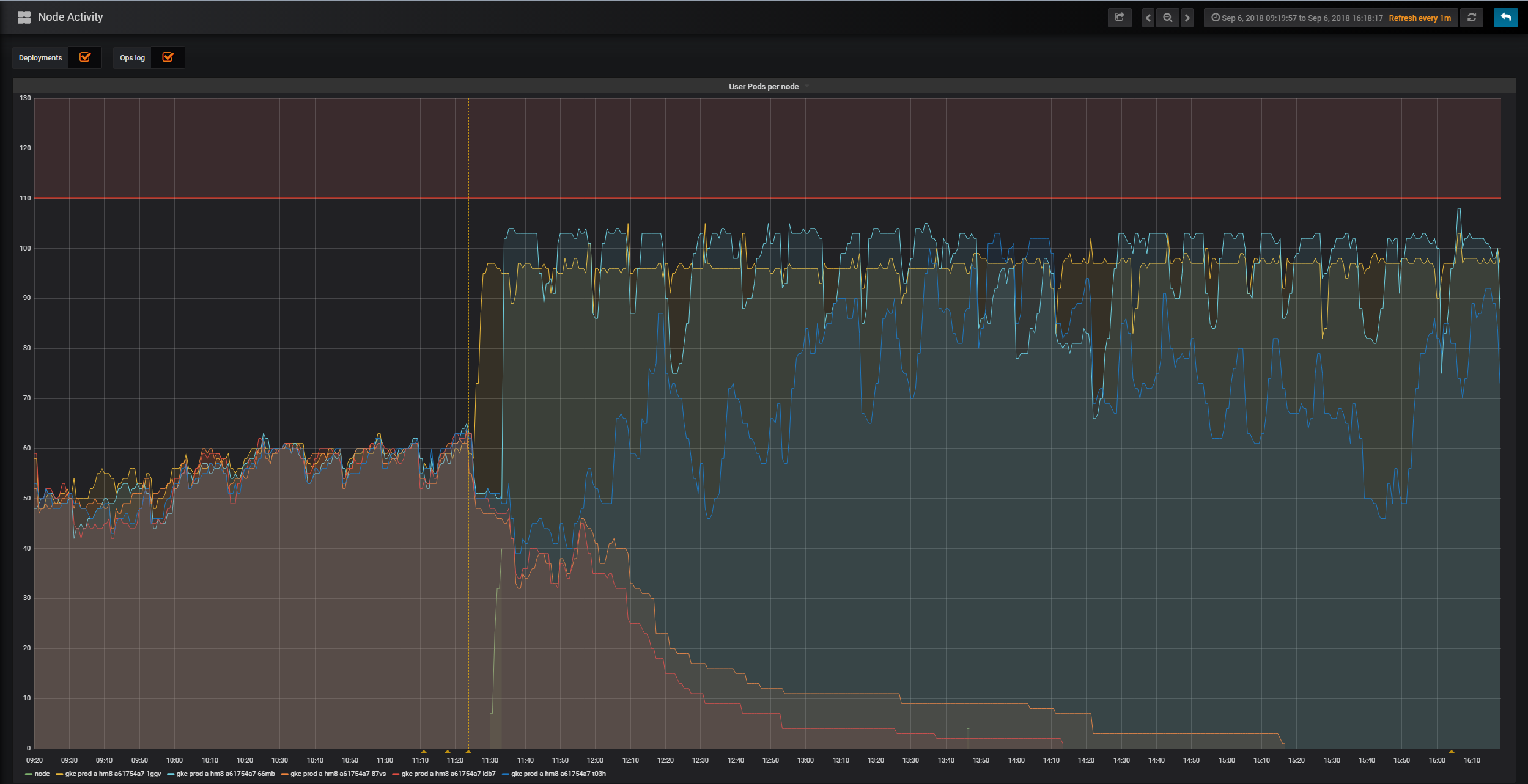
启用用户调度器
scheduling:
userScheduler:
enabled: true
注意:为了让用户调度器良好工作,您需要让旧的用户 pod 在某个时候关闭。请确保正确配置 culler。
平衡“保证”与“最大”内存和 CPU#
您可以为用户可用的内存和 CPU 选择一个“保证值”和一个“限制值”。这使您可以更有效地利用您的云资源,但如何选择正确的“保证值/限制值”的“比例”呢?这里有一个示例场景来帮助您决定策略。
考虑一个每个节点拥有 100G RAM 的 JupyterHub。Hub 的用户预计会偶尔使用 20G,所以您开始时给他们每个人保证 20G 的 RAM。这意味着任何时候用户启动他们的会话,节点上都会为他们保留 20G 的 RAM。每个节点可以容纳 5 个用户(100G / 每个用户 20G = 5 个用户)。
然而,您注意到在实践中,大多数用户只使用了 1G 的 RAM,并且极少使用全部 20G。这意味着您的 Hub 经常有 80 到 90G 的 RAM 被保留但未使用。您正在为您通常不需要的资源付费。
通过使用资源限制和保证,您可以更有效地利用您的云资源。资源限制定义了最大值,而资源保证定义了最小值。这两个数字的比率就是限制与保证的比率。在上述情况下,您的限制与保证的比率是 1:1。
如果您设置保证为 1GB,限制为 20GB,那么您的限制与保证比率为 20:1。您的节点平均可以容纳更多的用户。当一个用户启动会话时,如果节点上至少有 1GB 的 RAM 可用,那么他的会话将在那里启动。如果没有,将创建一个新节点(您的成本也随之增加)。
然而,假设现在这个节点上有 50 个用户。从技术上讲,这仍然远低于节点的最大允许数量,因为每个用户只保证了 1G 的 RAM,而我们总共有 100G。如果其中 10 个用户突然加载一个 10GB 的数据集,我们现在请求了 (10 * 10GB) + (40 * 1GB) = 140GB 已用 RAM。糟糕,我们现在远超 100GB 的限制,用户会话将开始崩溃。这就是当您的限制与保证比率过大时会发生的情况。
问题是什么?您的用户行为不适合您的限制与保证比率。您应该增加每个用户的保证 RAM 量,这样通常每个节点上的用户会更少,他们一次性请求 RAM 导致节点内存饱和的可能性也更小。
选择正确的限制与保证比率是一门艺术,而不是科学。我们建议从 2:1 的比率开始,然后根据您在 Hub 上是否遇到问题进行调整。例如,如果限制是 10GB,那么从 5GB 的保证开始。使用 Prometheus + Grafana 等服务来监控内存使用情况,并以此来决定是否调整您的比率。
为核心 Pod 的容器显式分配内存和 CPU#
Helm chart 会创建几个 k8s Pod,这些 Pod 通常运行一个容器,但有时会更多。在本节中,您将被引导如何通过请求(requests)来明确指定它们保证的 CPU 和内存量,以及通过限制(limits)来指定它们的 CPU 和内存上限。
为了补充本文,请参阅 Kubernetes 文档中的相关章节。
要决定设置什么样的请求和限制,一些背景知识是相关的:
资源请求保证了容器执行其工作所需的最低资源水平,而资源限制则声明了上限。
命名空间中的 LimitRange 资源可以为没有明确设置请求和/或限制的容器提供默认值。
请务必通过运行
kubectl get limitrange --namespace <k8s-namespace>来检查您部署 JupyterHub 的命名空间中是否存在此类资源。如果您设置了资源限制但省略了资源请求,那么 k8s 将假定您暗示的资源请求与您的限制相同。反之则不然。
竞争超出其请求的额外 CPU 的容器将以与其请求成比例的强度进行竞争。如果两个 CPU 资源请求分别为 0.1 和 0.4 的容器在一个 1 CPU 的节点上竞争 CPU,一个将获得 0.2,另一个将获得 0.8。
超额分配 CPU 会导致事情比它们本可以的更慢,但这通常不是灾难性的,而超额分配内存会导致容器进程被内存不足杀手(OOMKiller)终止。
这同样适用于配置不足:对 CPU 的低限制意味着事情可能会变慢,而对内存的低限制意味着事情会不断被杀死。
一个内存耗尽的容器,其进程将被 Linux 的 内存不足杀手 (OOMKiller) 杀死。当这种情况发生时,您应该可以通过使用
kubectl describe pod --namespace <k8s-namespace> <k8s-pod-name>和kubectl logs --previous --namespace <k8s-namespace> <k8s-pod-name>查看到它的痕迹。当一个容器的进程被杀死后,如果容器的
restartPolicy允许,容器将重新启动,否则 Pod 将被驱逐。一个完全被 CPU 剥夺的容器可能会以许多独特的方式出现问题,并且更难调试。各种超时可能是怀疑 CPU 饥饿的线索。
在节点上调度 Pod 时,会考虑 有效请求/限制。由于 Pod 的 init 容器在 Pod 的主容器启动前按顺序运行,因此有效请求/限制被计算为 init 容器请求/限制的最高值与主容器请求/限制的总和中的较大者。
软件可能无法利用超过 1 个 CPU,因为它不支持在多个 CPU 核心上并发运行代码。运行 Python 版 JupyterHub 的
hubPod 和运行 NodeJS 版 ConfigurableHTTPProxy 的proxyPod 就属于这类应用程序。
一些额外的技术细节
请求
0CPU 的容器将被授予 Kubernetes 容器运行时支持的最小 CPU 量。CPU 核心共享通常在 100 毫秒的时间间隔内在容器之间强制执行。
管理一个 k8s Pod 及其容器需要少量的 CPU 和内存开销,这将计入配额。
作为参考,您可以与 mybinder.org 部署中 JupyterHub Helm chart Pod 的 CPU 和内存使用情况进行比较,该部署运行一个 BinderHub,它依赖于这个 JupyterHub Helm chart。这些信息可以在 mybinder.org 的 Grafana 仪表盘中找到。
以下是您可以在此 Helm chart 中配置的各种资源请求以及一些相关说明。
配置 |
pod |
1.0.0 之前的 cpu/内存请求 |
注意 |
|---|---|---|---|
hub.resources |
hub |
200m, 510Mi |
JupyterHub 和 KubeSpawner 在此运行。可以用少量资源进行管理,但在同时有大量用户启动和停止服务器的极重负载下,CPU 峰值可达 1 个。 |
proxy.chp.resources |
proxy |
200m, 510Mi |
该容器运行 |
proxy.traefik.resources |
autohttps |
- |
该容器仅执行 TLS 终止。将需要少量资源。 |
proxy.secretSync.resources |
autohttps |
- |
sidecar 容器是一个看门狗,监视文件的变化并用这些变化更新一个 k8s Secret。将需要最少的资源。 |
scheduling.userScheduler.resources |
user-scheduler |
50m, 256Mi |
该容器运行一个带有自定义配置的 |
scheduling.userPlaceholder.resources |
user-placeholder |
- |
这是对重用 |
prePuller.resources |
hook|continuous-image-puller |
0, 0 |
这个 Pod 的所有容器都在运行 |
prePuller.hook.resources |
hook-image-awaiter |
0, 0 |
该容器只是轮询 k8s api-server。将需要最少的资源。 |
singleuser.cpu|memory.guarantee|limit |
jupyter-username |
0, 1G |
配置语法不同,因为它是 Spawner 基类原生的,而不是 Kubernetes 的。通常,保证一定量的内存而不是 CPU 会很有用,以帮助用户相互共享 CPU。 |
资源请求示例#
对于一个服务可靠性和性能很重要,但核心 pod 需要适应一个 2 CPU 节点的部署,这里有一些合理的资源请求示例。
# The ranges of CPU and memory in the comments represents the min - max values of
# resource usage for containers running in UC: Berkeley over 6 months.
hub: # hub pod, running jupyterhub/jupyterhub
resources:
requests:
cpu: 500m # 0m - 1000m
memory: 2Gi # 200Mi - 4Gi
proxy:
chp: # proxy pod, running jupyterhub/configurable-http-proxy
resources:
requests:
cpu: 500m # 0m - 1000m
memory: 256Mi # 100Mi - 600Mi
traefik: # autohttps pod (optional, running traefik/traefik)
resources:
requests:
cpu: 500m # 0m - 1000m
memory: 512Mi # 100Mi - 1.1Gi
secretSync: # autohttps pod (optional, sidecar container running small Python script)
resources:
requests:
cpu: 10m
memory: 64Mi
scheduling:
userScheduler: # user-scheduler pods (optional, running kubernetes/kube-scheduler)
resources:
requests:
cpu: 30m # 8m - 45m
memory: 512Mi # 100Mi - 1.5Gi
userPlaceholder: # user-placeholder pods (optional, running pause container)
# This is just an override of the resource requests that otherwise match
# those configured in singleuser.cpu|memory.guarantee|limit.
resources: {}
prePuller: # hook|continuous-image-puller pods (optional, running pause container)
resources:
requests:
cpu: 10m
memory: 8Mi
hook: # hook-image-awaiter pod (optional, running GoLang binary defined in images/image-awaiter)
resources:
requests:
cpu: 10m
memory: 8Mi
由于这些都是粗略估计的,请在 此 GitHub issue 中提供反馈,帮助我们改进它们。
注意
如果您在 k8s 集群中收集 Pod 资源使用情况的指标(Prometheus),并有显示其使用情况的仪表板(Grafana),您可以随着时间的推移调整这些值。